Blog
Insights from the data frontier
On data infrastructure, procurement, and the evolving data economy.
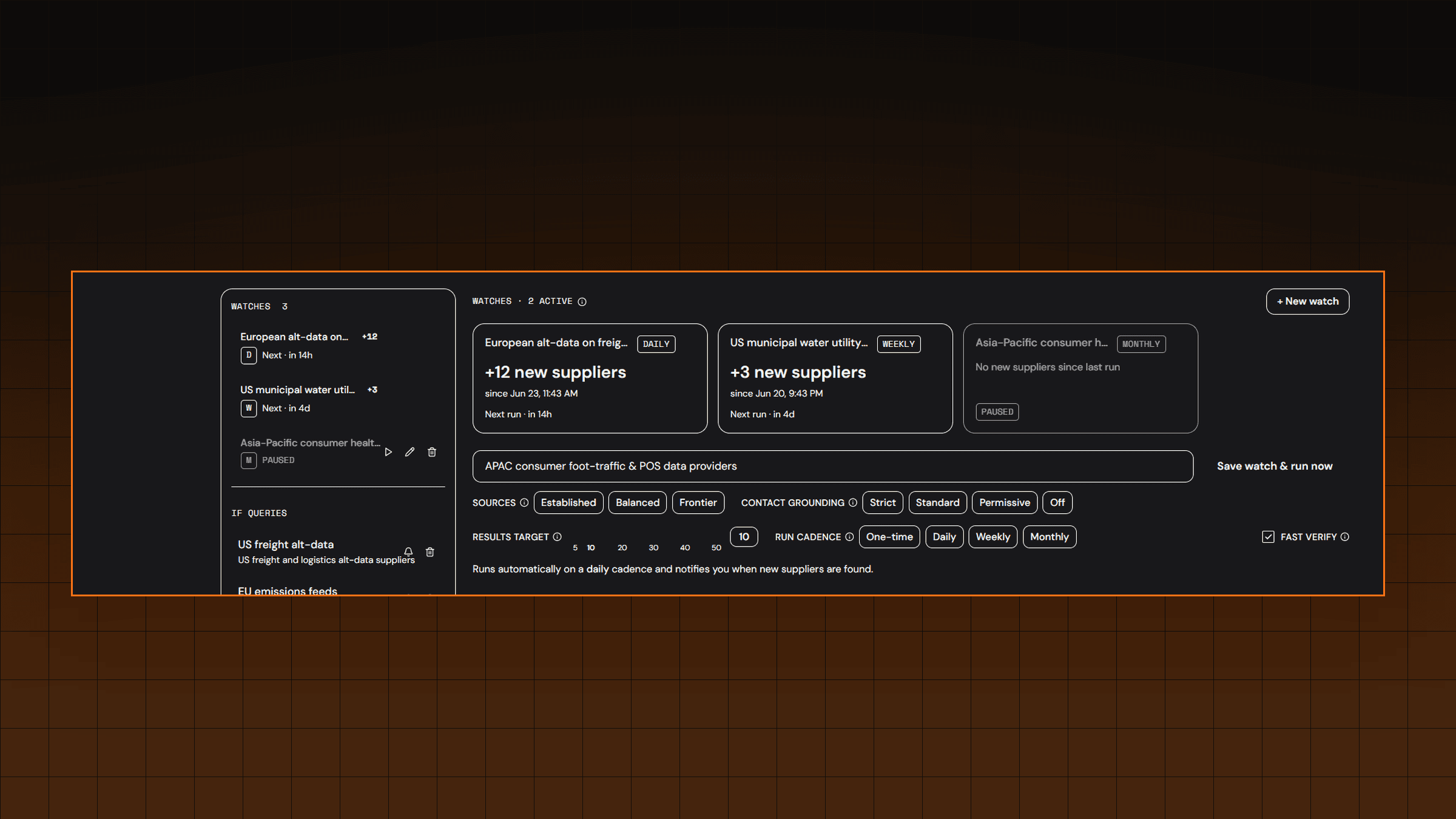
Changelog #3: Source Streams — Data Supplier Discovery on Autopilot
Source Streaming is now live on Brickroad. Set your thesis once, and your agent runs continuously, notifying you the moment a new data supplier comes online. Plus new APAC supplier discovery across China, Japan, Korea, and India; established-supplier views alongside frontier sources; and workspaces with category views for organizations running concurrent queries.
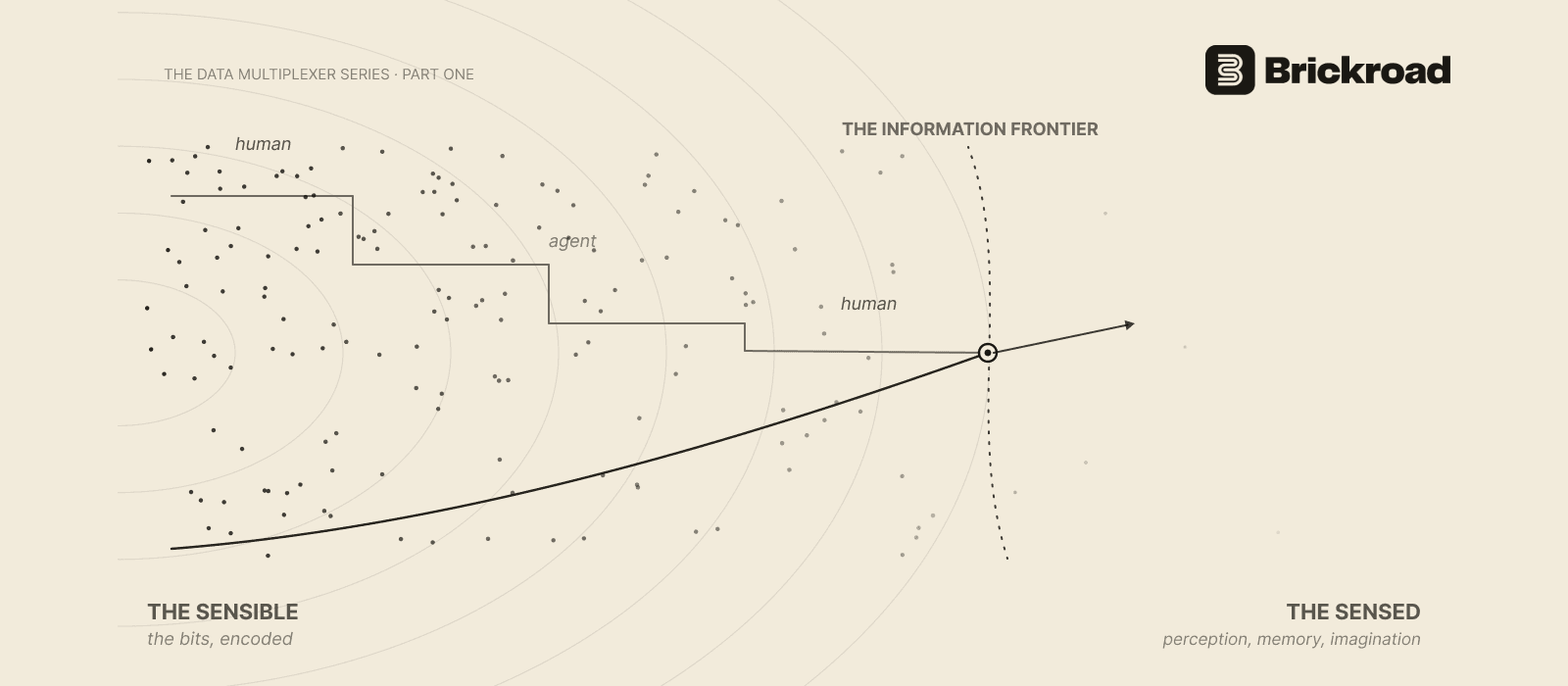
Neither Alone, Both in Sequence: Human-Agent Collaboration, Intellect, and the Information Frontier
Part 1 of The Data Multiplexer Series. The information frontier is structural and ever-widening; reaching it requires not just speed but intellect. Defining intellect, and why the frontier is reached by humans and agents only when paired in deliberate sequence — neither alone.
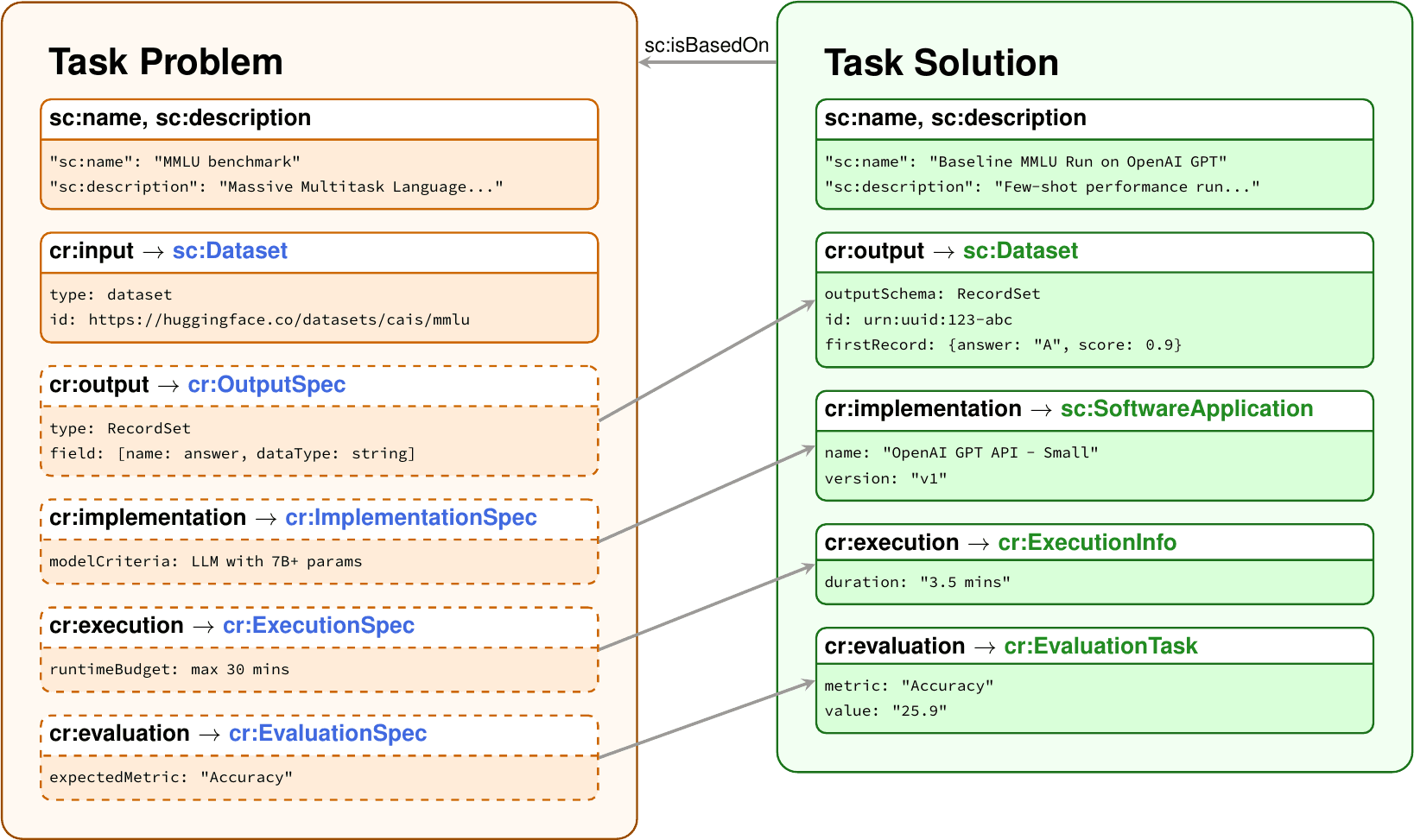
Croissant Tasks: Machine-Actionable Metadata for Reproducible ML Evaluations
Croissant Tasks is a declarative metadata format that turns benchmarks and competitions into machine-actionable specifications. It enables conceptual reproducibility: verifying a scientific claim through an independently generated implementation rather than brittle source-code replication.
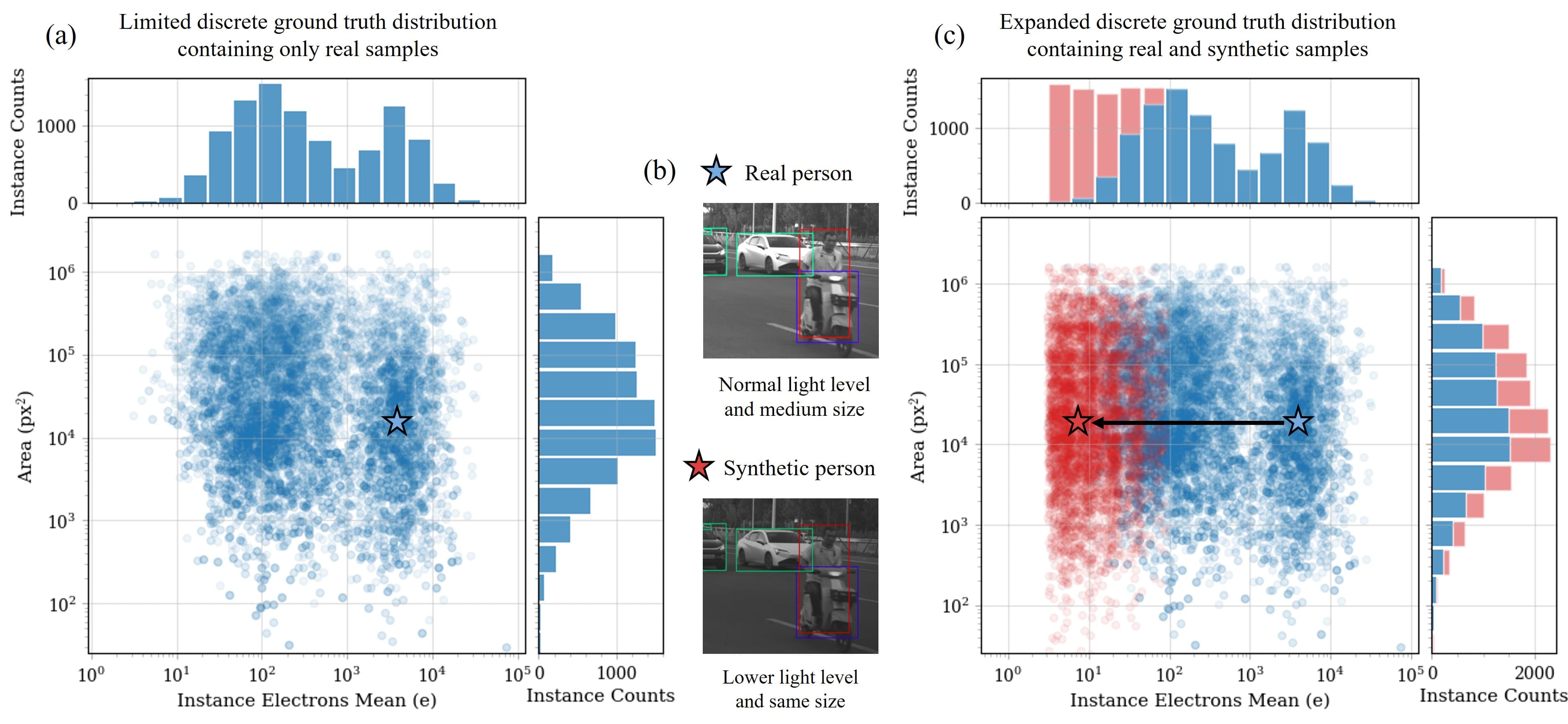
Making the Discrete Continuous: Synthetic RAW Augmentations for Low-Light Person Detection
Real datasets are sparse and uneven, which makes it hard to evaluate vision models where it matters most. By synthesizing physically faithful low-light RAW samples, we can turn a discrete, long-tailed variable into a continuous, controllable one and fairly characterize pedestrian detection in the dark.
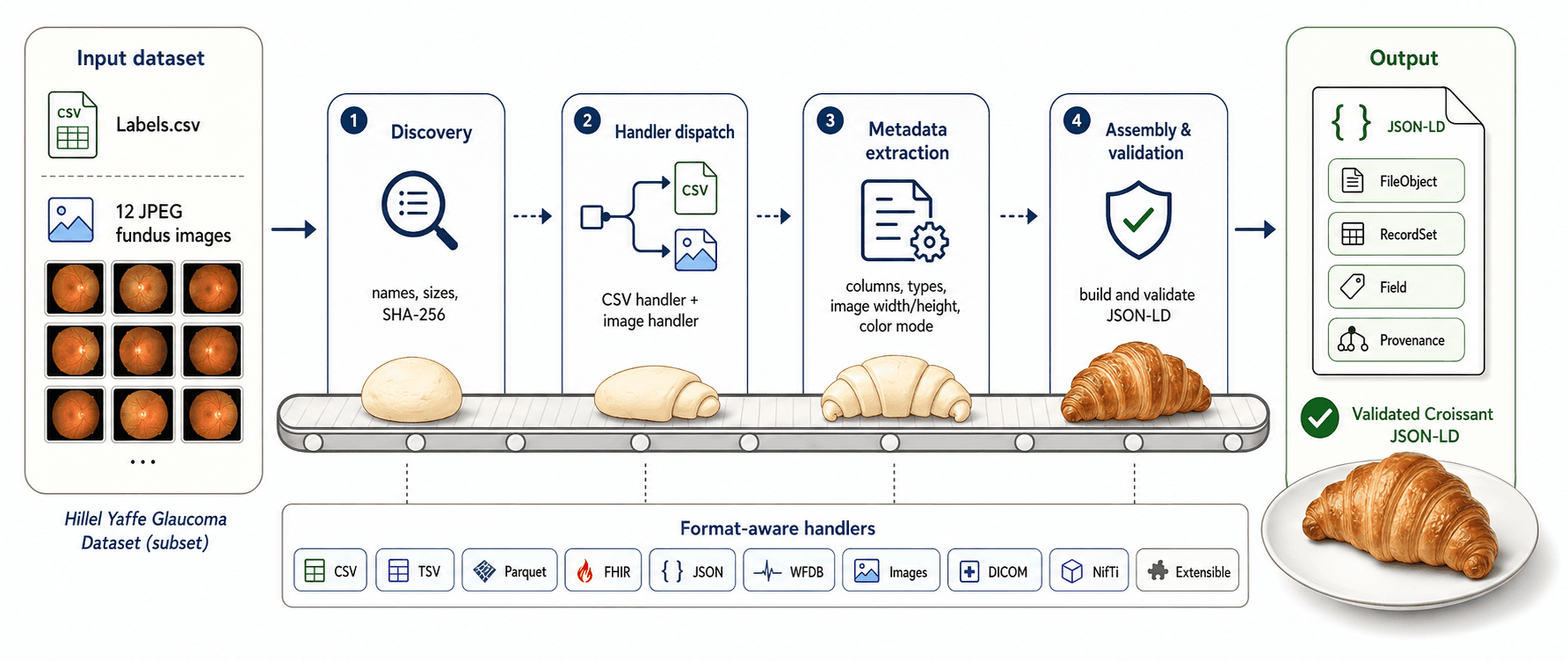
Croissant Baker: Local-First Metadata Generation for Governed ML Datasets
Croissant has become the metadata standard for ML datasets, but generating it usually means uploading data to a public platform — impossible for clinical, government, and enterprise data. Croissant Baker generates validated Croissant metadata locally, directly from a dataset directory, reaching 97-100% agreement with ground truth across domains and scaling to MIMIC-IV's 886 million rows.
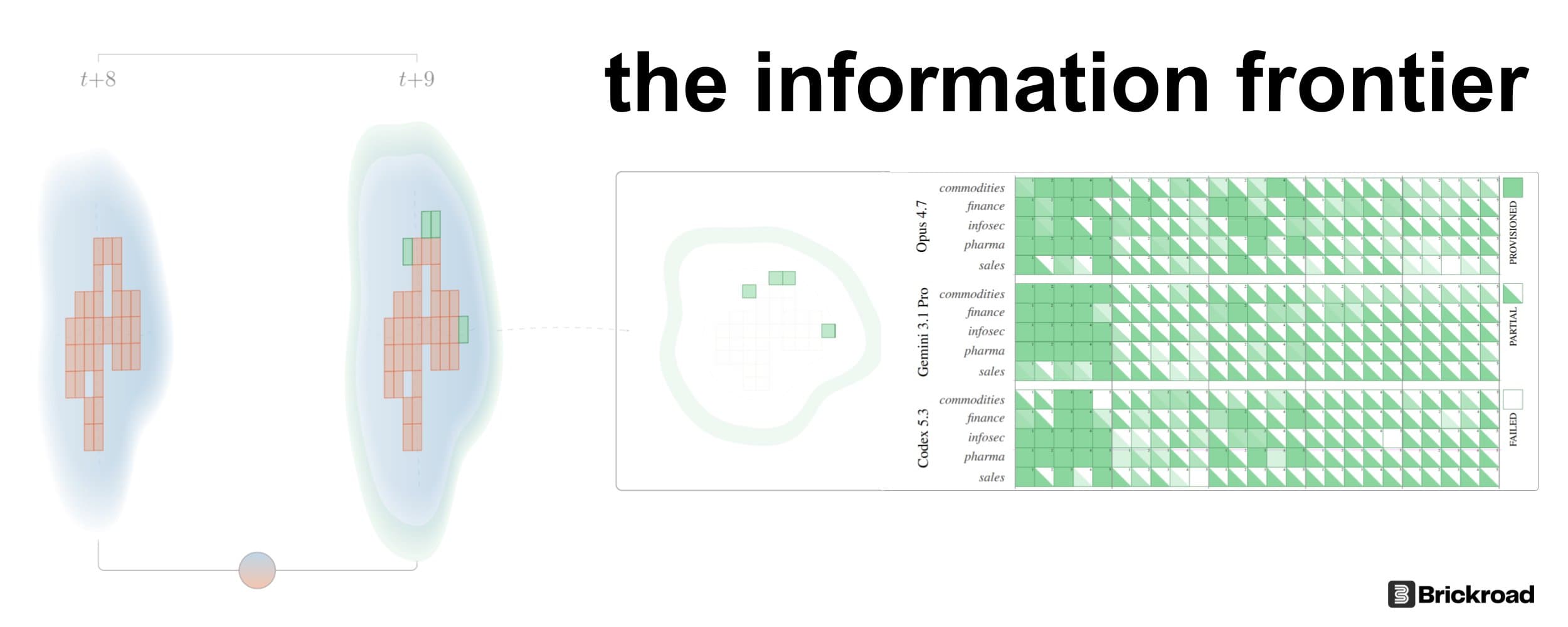
The Information Frontier
A reductionist view of machine learning as a perpetual data refinery, and a re-calibration of its primitives. Why the information frontier is perpetually expanding, what physics says about ever collapsing it, and what it implies for the learning systems we build and study.

The Geometry of Data Markets
Why data marketplaces won't lead to data liquidity: lessons from history. Data liquidity is real, but it requires the right shape. Not a catalog. Not a directory. Not a platform. A multiplexer, with agents underneath, routing the right data to the right endpoint at the right time.
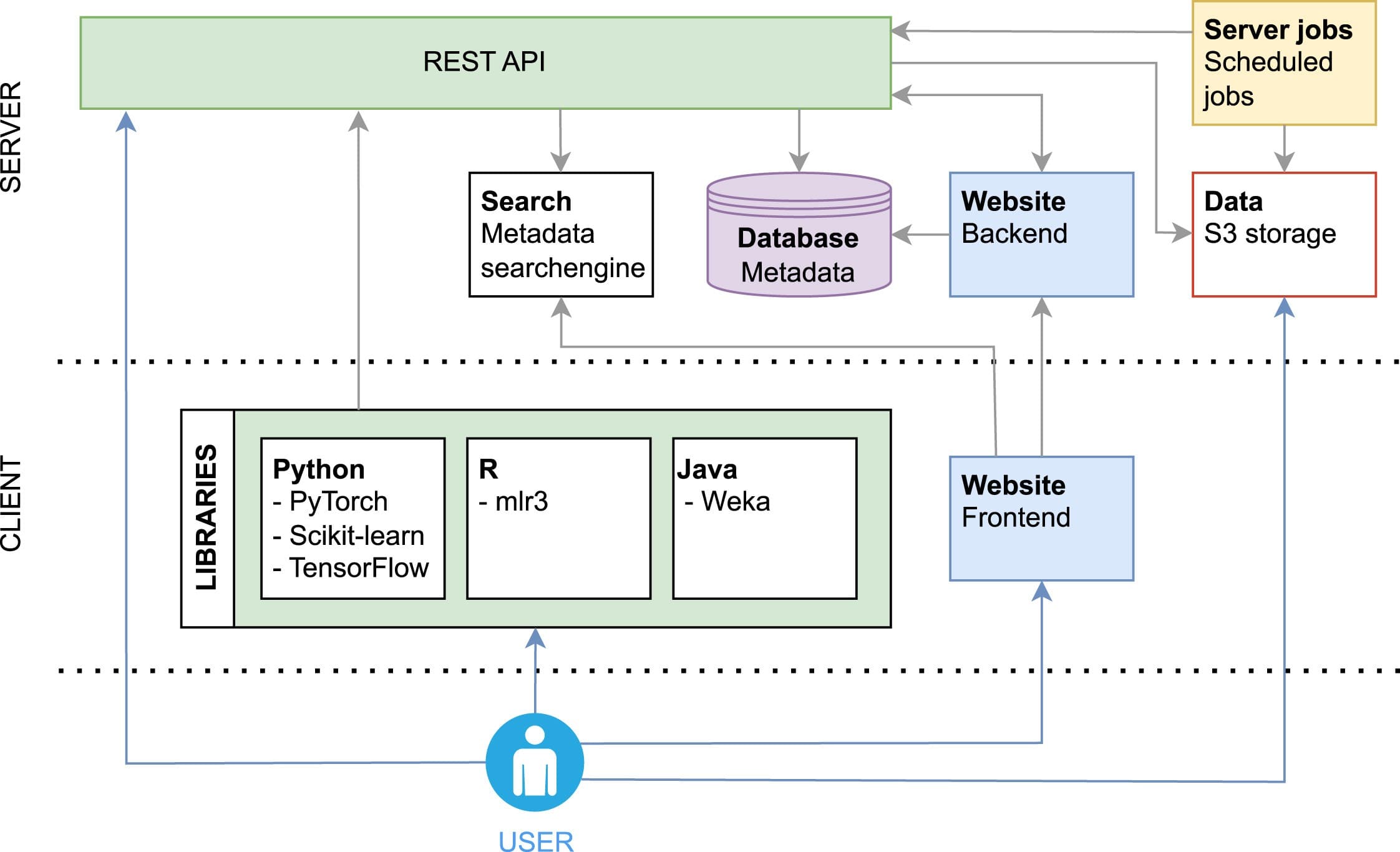
OpenML: Insights from 10 Years and More Than a Thousand Papers
A decade of OpenML, the open-source platform that turns machine-learning experiments into open, linked, and reusable knowledge. We look at the state of the ecosystem, how community-curated datasets, tasks, and benchmark suites have powered 1,500+ studies, and the lessons learned from building open-science infrastructure for ML.
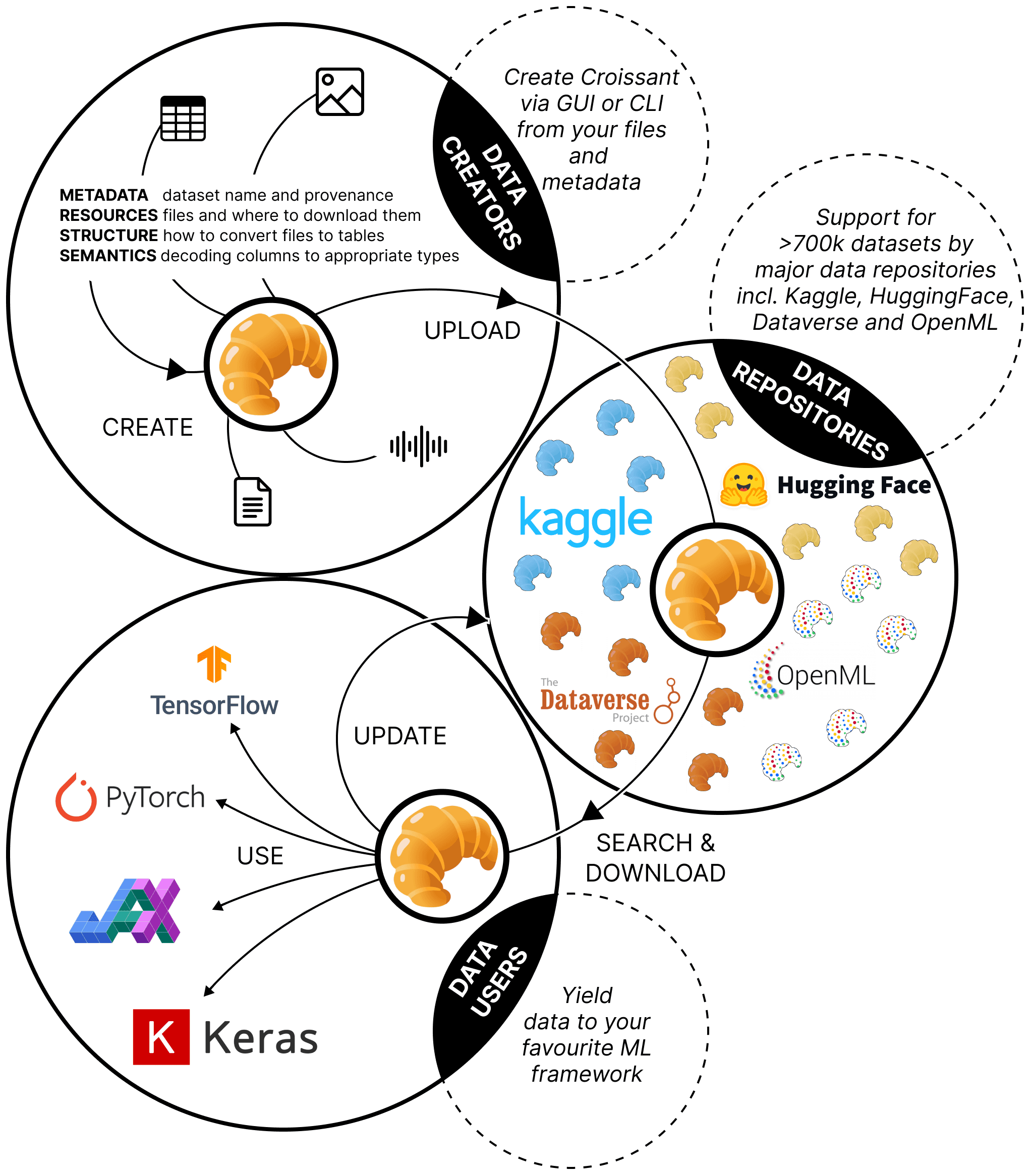
Croissant: A Metadata Format for ML-Ready Datasets
Working with data is still a key friction point in machine learning. Croissant is a metadata format that creates a shared representation across ML tools, frameworks, and platforms — making datasets discoverable, portable, and interoperable. It is already supported across repositories spanning hundreds of thousands of datasets.
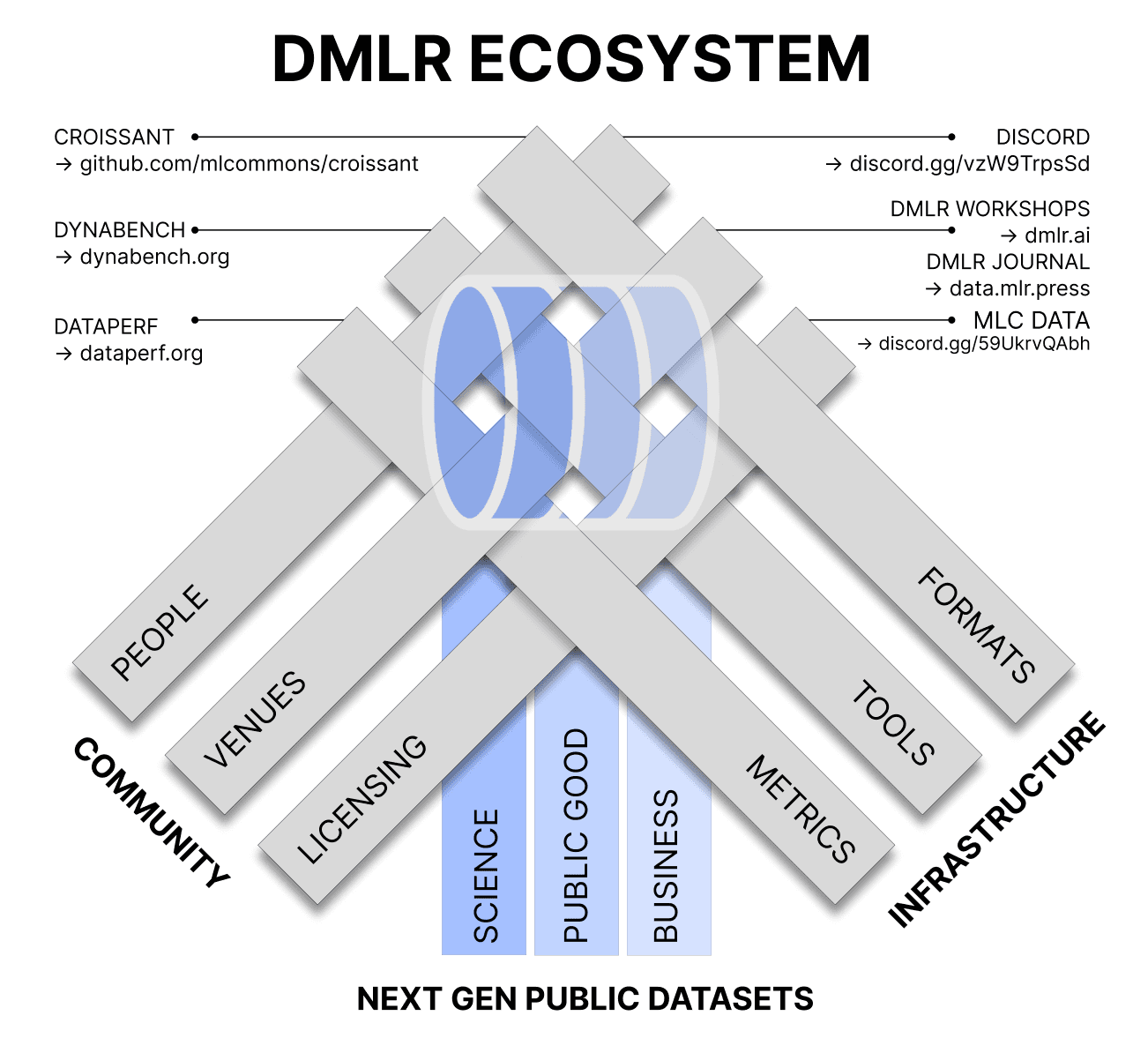
DMLR: Data-Centric Machine Learning Research — Past, Present and Future
Drawing on discussions at the inaugural DMLR workshop at ICML 2023, this editorial outlines why community engagement and infrastructure are essential to creating the next generation of public datasets — and charts a collective path to sustain them for scientific, societal, and business impact.